Basics of Machine Learning for Rising Healthcare Leadership
MHA Search
For the latest academic year, we have 170 schools in our MHAOnline.com database and those that advertise with us are labeled “sponsor”. When you click on a sponsoring school or program, or fill out a form to request information from a sponsoring school, we may earn a commission. View our advertising disclosure for more details.
In our last writing on healthcare technology, we explored the basics of artificial intelligence and reviewed some of the primary reasons for its lagging adoption within the sector.
In this piece, we will cover the complementary area of machine learning algorithms. While related, machine learning is not interchangeable with artificial intelligence. AI refers to the pursuit of developing computational systems which operate the way a human brain would operate in performing specific tasks.
AI can be thought of as a type of software program designed to behave the same way that a human would The environment and the tasks contained within it can range from simple to astonishingly complex. This is why AI is not necessarily more or less complex than machine learning.
It’s the human mimicry attribute that makes something artificial intelligence.
What is Machine Learning, and How Does It Relate to AI?
Machine learning (ML) refers to a set of computational algorithms that apply statistical modeling to a specific task. Think of a task as a question or an input. The algorithm uses logic applied to that question to generate an answer or output.
To emphasize the distinction between AI and ML, remember that AI refers to computational systems which mimic human behavior—ML refers to specific types of algorithms. Systems are built from algorithms; algorithms work inside of systems.
Not all algorithms are specifically ML algorithms. A “traditional” (i.e., a non-ML) algorithm—sometimes called an “expert rule system”—usually applies a deterministic approach. This means it can take an input, apply pre-programmed logic rules to it, and generate an output. It crunches numbers for single scenarios.
If there is no logic set up for that particular scenario, then the traditional algorithm can’t do much with it. It may crash or generate a null result, or something similarly unhelpful. An important distinction is that we always know why a traditional algorithm generated the output that it did. There is no ambiguity as far as understanding the logic underneath it. After all, programmers specifically built it to run in the desired way.
In sharp contrast, machine learning algorithms tend to work on the principle of a probabilistic approach. This writing won’t dive into the granular details of the mathematics, but the critical takeaway for readers is that with traditional algorithms, we always know why an input generated an output; with machine learning algorithms, we cannot always know why a particular output was generated in any given instance.
Calculus and statistics coursework is critical to truly understanding machine learning algorithms on a deeper level within clinical practice. Any readers considering pursuing an advanced degree stand to benefit a tremendous amount from the inclusion of coursework covering some statistics and calculus-level mathematics.
What we know about an ML algorithm’s inner workings is primarily gleaned from how the model was trained and tested. The learning step of ML model development is an important area to really grasp both their massive potential value and complex risks involved.
Training Machine Learning Models
Machine learning models are programmed indirectly by way of training them to determine how to apply logic to inputs and generate outputs. We can see the input, and we can see the output. Between those two points are one or more “hidden layers”—a phrase you’ve likely encountered in casual reading on the topic—and those hidden layers are where all the logic is hiding. We call them hidden layers not because we don’t know where they are, but rather because we can’t always definitively know what’s going on in them; as in, why a specific “question” generated a specific “answer” in that instance.
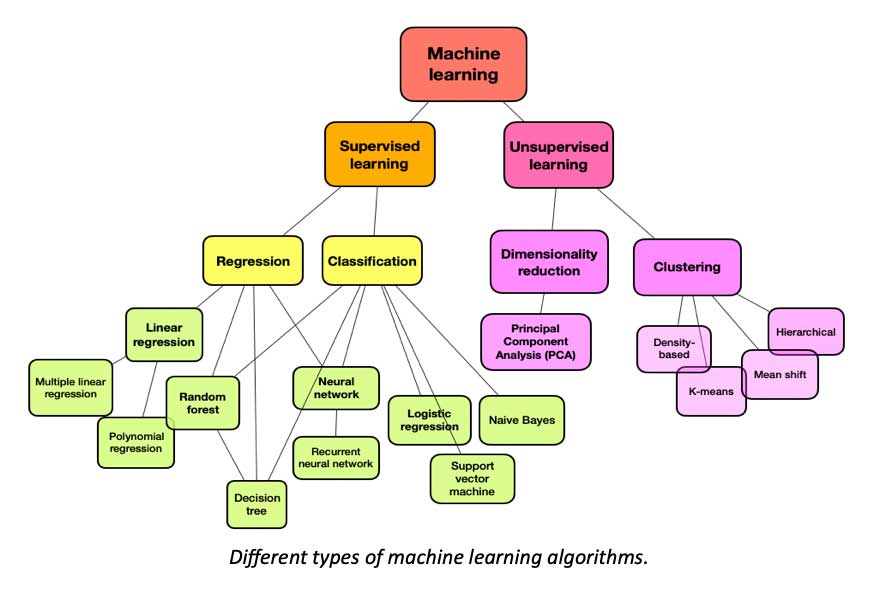
That’s not to say that ML algorithms operate willy-nilly, at least not supervised learning models. Supervised learning algorithms make up the overwhelming majority of those used in healthcare research and practice. Some techniques can be used to deduce what’s going on underneath their hood to some degree. To understand how that’s done, one must first understand how the training actually takes place.
Training ML algorithms begins with data—a lot of data. This training process entails feeding massive data sets that contain questions with identified answers into a training model. The labeling of the training data, is what makes this learning supervised, so that the correct answer to the associated question is identified.
This process can be easier to understand by thinking of “questions” in terms of images and “answers” as the correct label for any given image. This also happens to be one of the most frequently used applications of this technology within healthcare: imaging within radiology.
For example, imagine two pictures of apples and two pictures of bananas. The labeled fruits here represent our training dataset. The goal is to train our algorithm to correctly identify if the fruit image is an apple or a banana.
By feeding the model our training dataset, we are basically showing our algorithm a bunch of apples labeled as apples, and bananas labeled as bananas. We are demonstrating the correct question/response pairs. We repeat this many thousands of times.
Training Data is Big Data
How much of this data is required to train our algorithm sufficiently? Well, it really depends on the question being asked with the algorithm. But in general, the answer is a massive amount of training data.
The demand for big datasets in healthcare to train ML has driven the growth in recent decades of a massive market for real-world data. This market is selling data that originated from me, you, and everyone you know.
Importantly, when we are training our ML algorithm with labeled training data, we are not explaining why a banana is a banana. We are not providing measurement data relevant to the curve calculation of the average apple. We are simply providing a huge number of examples of how the question is correctly “answered.”
Once we believe that we have fed our model with sufficient data, the next step is testing without labels. This process involves—again—feeding it with big datasets. There is also the step of telling the model which images it has correctly labeled and which ones it gets wrong.
The errors and success are fed back into the algorithm and used to adjust the logic within the hidden layers to grow accuracy as more and more responses are validated.
What Happens Underneath the Hood
How does the trained model know the answer when those specific images have never been seen by it previously, only similar images? What decision-making processes are occurring when the model selects the output from the given input?
We generally can’t explain exactly what’s being decided to generate each output. When we do explore this to the deepest level possible, it involves complex mathematics, requiring both subject matter experts and statisticians to work together to tease out and explain their insights.
We know where the processes are taking place—it’s within the “hidden layers.” And sure, it can sound scary that we let this process do anything in healthcare once we realize this! We don’t exactly know how the algorithms make their decisions in every circumstance. We know the question we asked them; we can see the result through their response; we can run that response by a consensus panel of experts to see if they all agree.
But beyond that, we can’t see much further. We can’t force the algorithm to explain to us how and why it concluded what it did. We can only deduce the “thinking process,” so to speak, from observing a large number of responses from feeding in question after question, and examining the results.
Risk and Reward in Healthcare Application
Indeed, there seems to be an inherent danger to involving a process with such ambiguity within clinical care decision-making. But at the same time, something incredible is happening here. We must recognize that these algorithms often can answer questions correctly when they have never seen that exact question previously.
Consider that we have so many similar cases in healthcare, but no two human beings are identical. Neither are their medical histories and outcomes. An algorithm that can only work on the same cases has less potential value than one that can work effectively using data that is merely similar.
That capability of generating insights and guidance from similar but not the same type of data is a key attribute that renders these algorithms of such great tremendous value for healthcare. This value is so great that many experts and providers believe it can outweigh the costs of potential harm.
But it must be implemented with great care. This will be what distinguishes the greatest rising leaders within healthcare in coming years: the understanding to walk the tightrope between risk and reward.
Biased Data Makes Biased Models
A supervised learning model is only as good as the data used to train it. So what happens if the training data is not good? How do we know? How many errors can exist in training data before it becomes useless?
Considering how massive these datasets need to be, there really is no practical way to verify that every single data point is correct and free of bias. Particularly when using real-world data, that data inevitably is going to be littered with historical practice bias—and still seem accurate according to a lot of assessment tools.
Random sampling can be used to estimate how inaccurate our data is, but that’s not a perfect method, and it certainly doesn’t work well for addressing historically rooted bias that comes from practice records.
If the dataset can’t be completely checked for accuracy, can the trained model be checked instead? Well, sort of, but it’s also an imperfect science at best. This is another one of the big reasons for the yet limited adoption within actual practice. Being unable to explain why a healthcare decision by an algorithm that caused an adverse outcome for a patient was made is a substantial liability. An algorithm incorporating race, gender, or socioeconomic factors into recommendations can also be a substantial liability.
Beyond the challenges for calculating how medical malpractice is to account for such risk, many providers feel this stands in opposition to their commitment of, “Do no harm.” Many providers are still learning about the biases they subconsciously perpetuate themselves in their own clinical practice.
Nevertheless, the potential value of these algorithms is so significant that these risks are increasingly looked at as something to manage rather than fully avoid, and we are progressing as a society overall in learning to recognize and help mitigate historical bias. We have a long way to go, but the future is growing brighter for everyone daily.
ML Algorithms Will Inevitably Power the Future of Healthcare
Right now, most healthcare organizations have very limited adoption of these technologies on a large scale, but as far as piloting goes, more hospitals than not have begun taking steps in this direction. Most of these nascent programs are not designed to replace the decision-making of physicians and other providers, but rather to supplement it—to gain accuracy and reduce errors that can harm patients or waste limited resources.
A physician override or verification structure and decision process, while initially tending to increase the total workload, is still the safest approach to exploring future gains from these tools without taking on an unacceptable amount of risk.
Over time, ML algorithms will operate with a growing amount of autonomy. The time for leadership to explore pilot feasibility is now. Experts from the fields of medicine, technology, statistics, and legal must work together to develop the protocols and safeguards necessary to build out these projects. Healthcare leadership is uniquely tasked with consensus-building and pushing forward a more aggressive timeline while balancing risk.
The machine learning curve can be fairly steep, but there is no time like the present to begin climbing.
